Pass4itSure Microsoft DP-203 exam dumps are designed with the help of Microsoft’s real exam content. You can get DP-203 VCE dumps and DP-203 PDF dumps from Pass4itSure! Check out the best and updated DP-203 exam questions by Pass4itSure DP-203 dumps https://www.pass4itsure.com/dp-203.html (Q&As: 61) (VCE and PDF), we are very confident that you will be successful on the Microsoft DP-203 exam.
Microsoft DP-203 exam questions in PDF file
Download those Pass4itSure DP-203 pdf from Google Drive: https://drive.google.com/file/d/1YDM-X1bV-r636nqLbD8gxt29jN4_9DfK/view?usp=sharing
Microsoft Other Certifications
AI-102 Exam: Designing and Implementing a Microsoft Azure AI Solution (beta)
Free AI-102 Exam Questions Answers
https://www.microsoft-technet.com/get-pass4itsure-microsoft-ai-102-exam-dumps-as-practice-test-and-pdf.html
AI-900 Exam: Microsoft Azure AI Fundamentals
Free AI-102 Exam Questions Answers https://www.microsoft-technet.com/get-pass4itsure-microsoft-ai-900-exam-dumps-as-practice-test-and-pdf.html
AZ-140 Exam: Configuring and Operating Windows Virtual Desktop on Microsoft Azure
Free AZ-140 Exam Questions Answers https://www.microsoft-technet.com/get-pass4itsure-microsoft-az-140-exam-dumps-as-practice-test-and-pdf.html
AZ-220 Exam: Microsoft Azure IoT Developer
Free AZ-220 Exam Questions Answers https://www.microsoft-technet.com/get-pass4itsure-microsoft-az-220-exam-dumps-as-practice-test-and-pdf.html
AZ-600 Exam: Configuring and Operating a Hybrid Cloud with Microsoft Azure Stack Hub
Free AZ-600 Exam Questions Answers https://www.microsoft-technet.com/get-pass4itsure-microsoft-az-600-exam-dumps-as-practice-test-and-pdf.html
Following are some Microsoft DP-203 exam questions for review (Microsoft DP-203 practice test 1-13)
QUESTION 1
What should you do to improve high availability of the real-time data processing solution?
A. Deploy a High Concurrency Databricks cluster.
B. Deploy an Azure Stream Analytics job and use an Azure Automation runbook to check the status of the job and to
start the job if it stops.
C. Set Data Lake Storage to use geo-redundant storage (GRS).
D. Deploy identical Azure Stream Analytics jobs to paired regions in Azure.
Correct Answer: D
Guarantee Stream Analytics job reliability during service updates Part of being a fully managed service is the capability
to introduce new service functionality and improvements at a rapid pace. As a result, Stream Analytics can have a
service update deploy on a weekly (or more frequent) basis. No matter how much testing is done there is still a risk that
an existing, running job may break due to the introduction of a bug. If you are running mission critical jobs, these risks
need to be avoided. You can reduce this risk by following Azure\\’s paired region model.
Scenario: The application development team will create an Azure event hub to receive real-time sales data, including
store number, date, time, product ID, customer loyalty number, price, and discount amount, from the point of sale (POS)
system and output the data to data storage in Azure
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-job-reliability
QUESTION 2
HOTSPOT
You need to output files from Azure Data Factory.
Which file format should you use for each type of output? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

Box 1: Parquet
Parquet stores data in columns, while Avro stores data in a row-based format. By their very nature, column-oriented
data stores are optimized for read-heavy analytical workloads, while row-based databases are best for write-heavy
transactional workloads.
Box 2: Avro
An Avro schema is created using JSON format.
AVRO supports timestamps.
Note: Azure Data Factory supports the following file formats (not GZip or TXT).
Avro format
Binary format
Delimited text format
Excel format
JSON format
ORC format
Parquet format
XML format
Reference:
https://www.datanami.com/2018/05/16/big-data-file-formats-demystified
QUESTION 3
You have a partitioned table in an Azure Synapse Analytics dedicated SQL pool. You need to design queries to
maximize the benefits of partition elimination. What should you include in the Transact-SQL queries?
A. JOIN
B. WHERE
C. DISTINCT
D. GROUP BY
Correct Answer: B
QUESTION 4
What should you recommend to prevent users outside the Litware on-premises network from accessing the analytical
data store?
A. a server-level virtual network rule
B. a database-level virtual network rule
C. a server-level firewall IP rule
D. a database-level firewall IP rule
Correct Answer: A
Scenario: Ensure that the analytical data store is accessible only to the company\\’s on-premises network and Azure
services.
Virtual network rules are one firewall security feature that controls whether the database server for your single
databases and elastic pool in Azure SQL Database or for your databases in SQL Data Warehouse accepts
communications that are sent from particular subnets in virtual networks.
Server-level, not database-level: Each virtual network rule applies to your whole Azure SQL Database server, not just to
one particular database on the server. In other words, virtual network rule applies at the server-level, not at the
database-level.
Reference: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-vnet-service-endpoint-rule-overview
QUESTION 5
You have an Azure data factory.
You need to examine the pipeline failures from the last 60 days.
What should you use?
A. the Activity log blade for the Data Factory resource
B. the Monitor and Manage app in Data Factory
C. the Resource health blade for the Data Factory resource
D. Azure Monitor
Correct Answer: D
Data Factory stores pipeline-run data for only 45 days. Use Azure Monitor if you want to keep that data for a longer
time.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/monitor-using-azure-monitor
QUESTION 6
You have an Azure Synapse workspace named MyWorkspace that contains an Apache Spark database named
mytestdb.
You run the following command in an Azure Synapse Analytics Spark pool in MyWorkspace.
CREATE TABLE mytestdb.myParquetTable(
EmployeeID int,
EmployeeName string,
EmployeeStartDate date)
USING Parquet
You then use Spark to insert a row into mytestdb.myParquetTable. The row contains the following data.

One minute later, you execute the following query from a serverless SQL pool in MyWorkspace.
SELECT EmployeeID FROM mytestdb.dbo.myParquetTable WHERE name = \\’Alice\\’;
What will be returned by the query?
A. 24
B. an error
C. a null value
Correct Answer: A
Once a database has been created by a Spark job, you can create tables in it with Spark that use Parquet as the
storage format. Table names will be converted to lower case and need to be queried using the lower case name. These
tables will immediately become available for querying by any of the Azure Synapse workspace Spark pools. They can
also be used from any of the Spark jobs subject to permissions.
Note: For external tables, since they are synchronized to serverless SQL pool asynchronously, there will be a delay until
they appear.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/metadata/table
QUESTION 7
You are designing an Azure Databricks table. The table will ingest an average of 20 million streaming events per day.
You need to persist the events in the table for use in incremental load pipeline jobs in Azure Databricks. The solution
must minimize storage costs and incremental load times.
What should you include in the solution?
A. Partition by DateTime fields.
B. Sink to Azure Queue storage.
C. Include a watermark column.
D. Use a JSON format for physical data storage.
Correct Answer: B
The Databricks ABS-AQS connector uses Azure Queue Storage (AQS) to provide an optimized file source that lets you
find new files written to an Azure Blob storage (ABS) container without repeatedly listing all of the files. This provides
two
major advantages:
Lower latency: no need to list nested directory structures on ABS, which is slow and resource intensive.
Lower costs: no more costly LIST API requests made to ABS.
Reference:
https://docs.microsoft.com/en-us/azure/databricks/spark/latest/structured-streaming/aqs
QUESTION 8
DRAG DROP
You need to ensure that the Twitter feed data can be analyzed in the dedicated SQL pool. The solution must meet the
customer sentiment analytic requirements.
Which three Transact-SQL DDL commands should you run in sequence? To answer, move the appropriate commands
from the list of commands to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
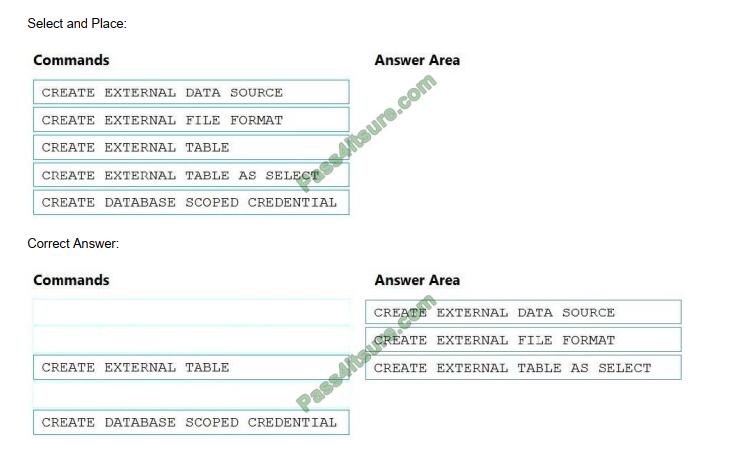
Scenario: Allow Contoso users to use PolyBase in an Azure Synapse Analytics dedicated SQL pool to query the content
of the data records that host the Twitter feeds. Data must be protected by using row-level security (RLS). The users
must
be authenticated by using their own Azure AD credentials.
Box 1: CREATE EXTERNAL DATA SOURCE
External data sources are used to connect to storage accounts.
Box 2: CREATE EXTERNAL FILE FORMAT
CREATE EXTERNAL FILE FORMAT creates an external file format object that defines external data stored in Azure
Blob Storage or Azure Data Lake Storage. Creating an external file format is a prerequisite for creating an external
table.
Box 3: CREATE EXTERNAL TABLE AS SELECT
When used in conjunction with the CREATE TABLE AS SELECT statement, selecting from an external table imports
data into a table within the SQL pool. In addition to the COPY statement, external tables are useful for loading data.
Incorrect Answers:
CREATE EXTERNAL TABLE
The CREATE EXTERNAL TABLE command creates an external table for Synapse SQL to access data stored in Azure
Blob Storage or Azure Data Lake Storage.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-tables-external-tables
QUESTION 9
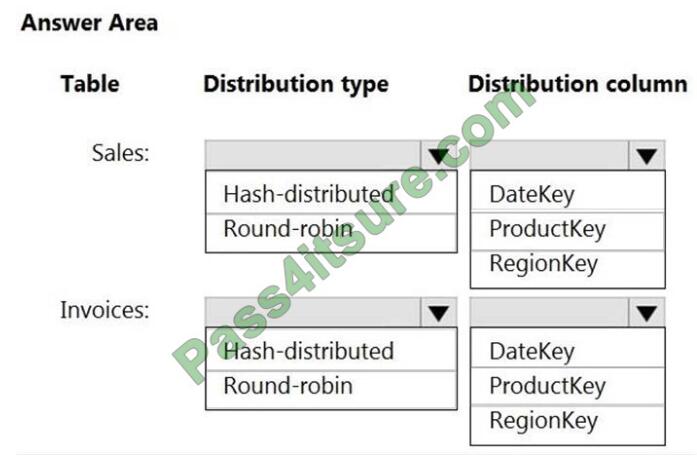
HOTSPOT
You have an on-premises data warehouse that includes the following fact tables. Both tables have the following
columns: DateKey, ProductKey, RegionKey. There are 120 unique product keys and 65 unique region keys.

Queries that use the data warehouse take a long time to complete.
You plan to migrate the solution to use Azure Synapse Analytics. You need to ensure that the Azure-based solution
optimizes query performance and minimizes processing skew.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point
Hot Area:
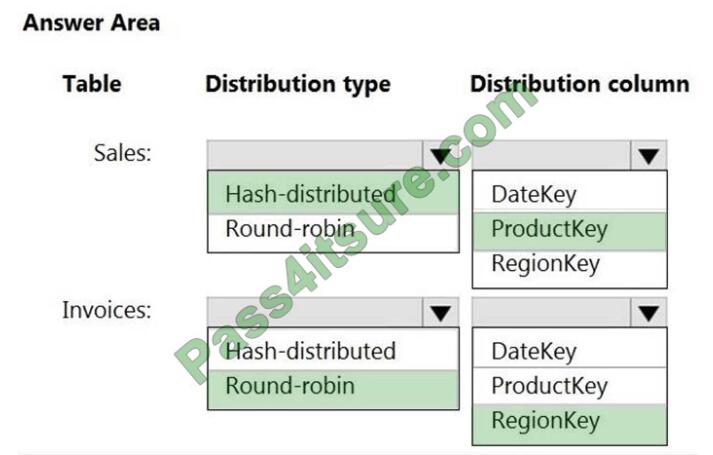
Correct Answer:
QUESTION 10
You are monitoring an Azure Stream Analytics job.
The Backlogged Input Events count has been 20 for the last hour.
You need to reduce the Backlogged Input Events count.
What should you do?
A. Drop late arriving events from the job.
B. Add an Azure Storage account to the job.
C. Increase the streaming units for the job.
D. Stop the job.
Correct Answer: C
General symptoms of the job hitting system resource limits include:
If the backlog event metric keeps increasing, it\\’s an indicator that the system resource is constrained (either because
of output sink throttling, or high CPU).
Note: Backlogged Input Events: Number of input events that are backlogged. A non-zero value for this metric implies
that your job isn\\’t able to keep up with the number of incoming events. If this value is slowly increasing or consistently
nonzero, you should scale out your job: adjust Streaming Units.
Reference:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-scale-jobs
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-monitoring
QUESTION 11
You have an Azure Databricks workspace named workspace1 in the Standard pricing tier.
You need to configure workspace1 to support autoscaling all-purpose clusters. The solution must meet the following
requirements:
Automatically scale down workers when the cluster is underutilized for three minutes.
Minimize the time it takes to scale to the maximum number of workers.
Minimize costs.
What should you do first?
A. Enable container services for workspace1.
B. Upgrade workspace1 to the Premium pricing tier.
C. Set Cluster Mode to High Concurrency.
D. Create a cluster policy in workspace1.
Correct Answer: B
For clusters running Databricks Runtime 6.4 and above, optimized autoscaling is used by all-purpose clusters in the
Premium plan Optimized autoscaling:
Scales up from min to max in 2 steps.
Can scale down even if the cluster is not idle by looking at shuffle file state.
Scales down based on a percentage of current nodes.
On job clusters, scales down if the cluster is underutilized over the last 40 seconds.
On all-purpose clusters, scales down if the cluster is underutilized over the last 150 seconds.
The spark.databricks.aggressiveWindowDownS Spark configuration property specifies in seconds how often a cluster
makes down-scaling decisions. Increasing the value causes a cluster to scale down more slowly. The maximum value
is
600.
Note: Standard autoscaling
Starts with adding 8 nodes. Thereafter, scales up exponentially, but can take many steps to reach the max. You can
customize the first step by setting the spark.databricks.autoscaling.standardFirstStepUp Spark configuration property.
Scales down only when the cluster is completely idle and it has been underutilized for the last 10 minutes.
Scales down exponentially, starting with 1 node.
Reference:
https://docs.databricks.com/clusters/configure.html
QUESTION 12
You have an Azure Synapse Analytics dedicated SQL pool.
You need to ensure that data in the pool is encrypted at rest. The solution must NOT require modifying applications that
query the data.
What should you do?
A. Enable encryption at rest for the Azure Data Lake Storage Gen2 account.
B. Enable Transparent Data Encryption (TDE) for the pool.
C. Use a customer-managed key to enable double encryption for the Azure Synapse workspace.
D. Create an Azure key vault in the Azure subscription grant access to the pool.
Correct Answer: B
Transparent Data Encryption (TDE) helps protect against the threat of malicious activity by encrypting and decrypting
your data at rest. When you encrypt your database, associated backups and transaction log files are encrypted without
requiring any changes to your applications. TDE encrypts the storage of an entire database by using a symmetric key
called the database encryption key.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-overviewmanage-security
QUESTION 13
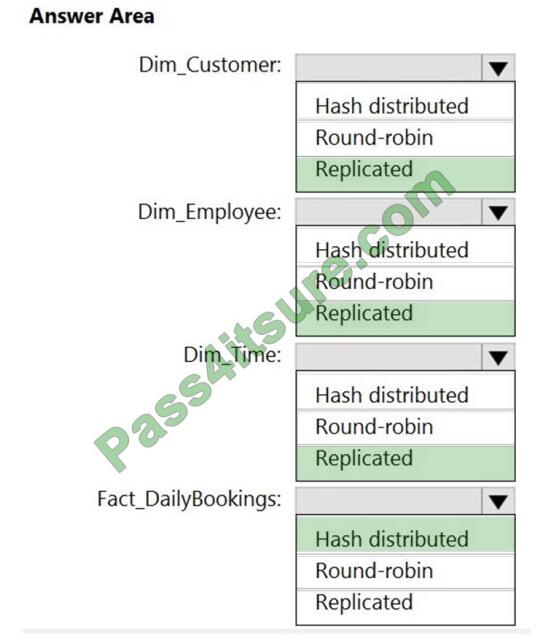
HOTSPOT
You have a data model that you plan to implement in a data warehouse in Azure Synapse Analytics as shown in the
following exhibit.
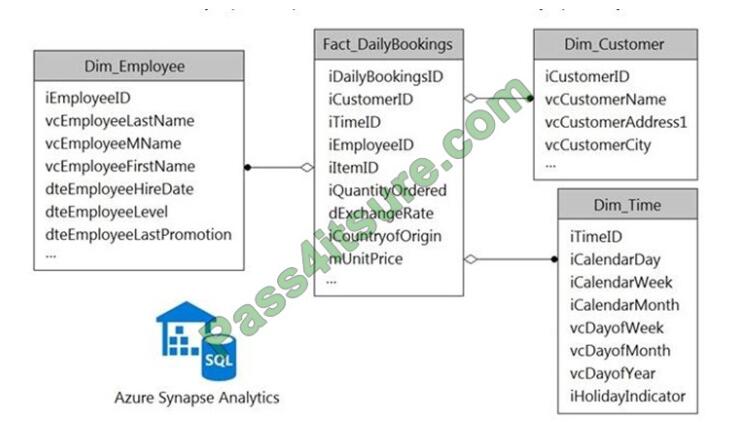
All the dimension tables will be less than 2 GB after compression, and the fact table will be approximately 6 TB. Which
type of table should you use for each table? To answer, select the appropriate options in the answer area. NOTE: Each
correct selection is worth one point.
Hot Area:

Correct Answer:
PS.
Thanks for reading! Hope the newest DP-203 exam dumps can help you in your exam. Get full DP-203 exam questions to try Pass4itSure DP-203 dumps! DP-203 dumps in VCE and PDF are here: https://www.pass4itsure.com/dp-203.html (Updated: Jul 06, 2021).
Download Pass4itSure DP-203 dumps pdf from Google Drive: https://drive.google.com/file/d/1YDM-X1bV-r636nqLbD8gxt29jN4_9DfK/view?usp=sharing (DP-203 Exam Questions)