
Microsoft DP-203 dumps bring new opportunities for test-takers. It accounts for an increasing share of consumption, so finding the right DP-203 dumps material became key to successfully passing the Data Engineering on the Microsoft Azure exam.
Real DP-203 dumps https://www.pass4itsure.com/dp-203.html Q&As Total: 239
Who is the Data Engineering on Microsoft Azure DP-203 exam?
Exam DP-203: Data Engineering on Microsoft Azure
This exam measures your ability to accomplish the following technical tasks: design and implement data storage; design and develop data processing; design and implement data security; and monitor and optimize data storage and data processing.
Pass the exam to earn Microsoft Certified: Azure Data Engineer Associate.
It has become the primary exam for Microsoft certification.
How the Microsoft DP-203 dumps helps pass the exam?
In today’s generation, there are thousands of things every day, and there is very little time at the discretion of individuals. There are also contemporary people with very short attention spans, usually only about 8 seconds. To combat this trend, new testing methods are also emerging, such as the Pass4itSure DP-203 dumps, which have been popular in recent years and are effective for passing the Microsoft DP-203 exam.
Pass4itSure DP-203 dumps It is available in both forms of PDF and VCE, free choice, free learning.
Although there are many new forms to use, the DP-203 dumps are still the main force that passes the DP-203 exam.
Read on, and then the highlights.
Share a free Microsoft DP-203 dumps PDF, practice test online, and be more efficient
The correct answer is posted at the end of the question, practice first, and then compare the answer.
Microsoft Certified: Azure Data Engineer Associate DP-203 practice test online
Q1:
You are performing exploratory analysis of the bus fare data in an Azure Data Lake Storage Gen2 account by using an
Azure Synapse Analytics serverless SQL pool. You execute the Transact-SQL query shown in the following exhibit.
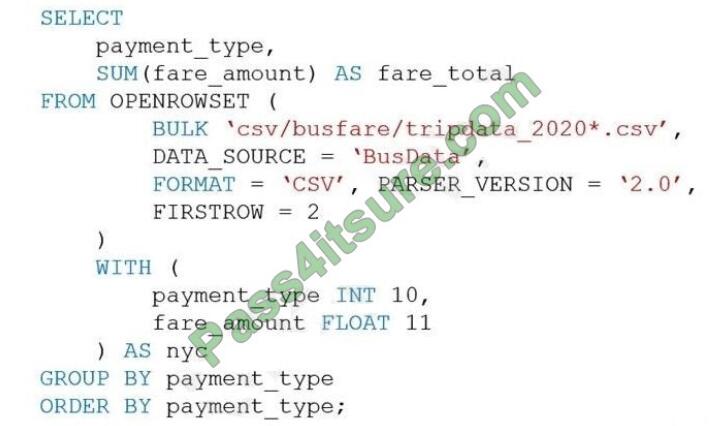
What do the query results include?
A. Only CSV files in the tripdata_2020 subfolder.
B. All files that have file names that begin with “tripdata_2020”.
C. All CSV files that have file names that contain “tripdata_2020”.
D. Only CSV that have file names that begin with “tripdata_2020”.
Q2:
You are designing a star schema for a dataset that contains records of online orders. Each record includes an order
date, an order due date, and an order ship date. You need to ensure that the design provides the fastest query times of
the records when querying for arbitrary date ranges and aggregating by fiscal calendar attributes.
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one
point.
A. Create a date dimension table that has a DateTime key.
B. Use built-in SQL functions to extract data attributes.
C. Create a date dimension table that has an integer key in the format of YYYYMMDD.
D. In the fact table, use integer columns for the date fields.
E. Use DateTime columns for the date fields.
Q3:
You plan to build a structured streaming solution in Azure Databricks. The solution will count new events in five-minute
intervals and report only events that arrive during the interval. The output will be sent to a Delta Lake table. Which
output mode should you use?
A. update
B. complete
C. append
Append Mode: Only new rows appended in the result table since the last trigger are written to external storage. This is
applicable only for the queries where existing rows in the Result Table are not expected to change.
Incorrect Answers:
B: Complete Mode: The entire updated result table is written to external storage. It is up to the storage connector to
decide how to handle the writing of the entire table.
A: Update Mode: Only the rows that were updated in the result table since the last trigger are written to external storage.
This is different from Complete Mode in that Update Mode outputs only the rows that have changed since the last
trigger. If the query doesn\\’t contain aggregations, it is equivalent to Append mode.
Reference: https://docs.databricks.com/getting-started/spark/streaming.html
Q4:
You are monitoring an Azure Stream Analytics job.
The Backlogged Input Events count has been 20 for the last hour.
You need to reduce the Backlogged Input Events count.
What should you do?
A. Drop late-arriving events from the job.
B. Add an Azure Storage account to the job.
C. Increase the streaming units for the job.
D. Stop the job.
General symptoms of the job hitting system resource limits include:
If the backlog event metric keeps increasing, it\’s an indicator that the system resource is constrained (either because
of output sink throttling or high CPU).
Note: Backlogged Input Events: Number of input events that are backlogged. A non-zero value for this metric implies
that your job isn\’t able to keep up with the number of incoming events. If this value is slowly increasing or consistently
nonzero, you should scale out your job: adjust Streaming Units.
Reference:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-scale-jobs
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-monitoring
Q5:
You are designing a sales transactions table in an Azure Synapse Analytics dedicated SQL pool. The table will contain
approximately 60 million rows per month and will be partitioned by month. The table will use a clustered column store
index and round-robin distribution.
Approximately how many rows will there be for each combination of distribution and partition?
A. 1 million
B. 5 million
C. 20 million
D. 60 million
Q6:
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear on the review screen.
You have an Azure Storage account that contains 100 GB of files. The files contain rows of text and numerical values.
75% of the rows contain description data that has an average length of 1.1 MB.
You plan to copy the data from the storage account to an enterprise data warehouse in Azure Synapse Analytics.
You need to prepare the files to ensure that the data copies quickly.
Solution: You convert the files to compressed delimited text files.
Does this meet the goal?
A. Yes
B. No
All file formats have different performance characteristics. For the fastest load, use compressed delimited text files.
Reference: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/guidance-for-loading-data
Q7:
HOTSPOT
The storage account container view is shown in the Refdata exhibit. (Click the Refdata tab.) You need to configure the
Stream Analytics job to pick up the new reference data. What should you configure? To answer, select the appropriate
options in the answer area NOTE:
Each correct selection is worth one point.
Hot Area:
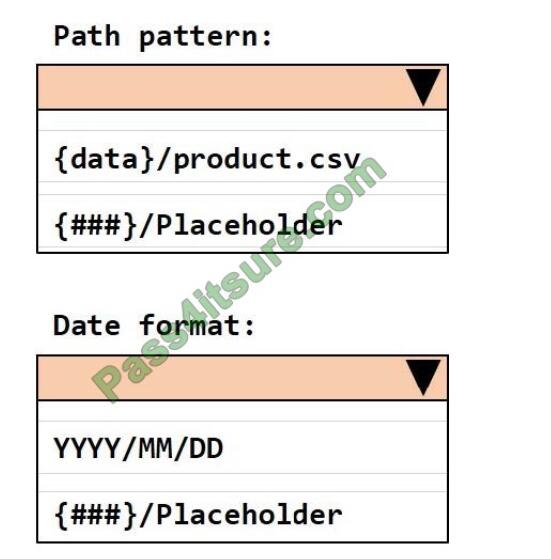
Correct Answer:

Q8:
DRAG-DROP
You need to create an Azure Data Factory pipeline to process data for the following three departments at your
company: ecommerce, retail, and wholesale. The solution must ensure that data can also be processed for the entire
company.
How should you complete the Data Factory data flow script? To answer, drag the appropriate values to the correct
targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes
or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:

The conditional split transformation routes data rows to different streams based on matching conditions. The conditional split transformation is similar to a CASE decision structure in a programming language. The transformation evaluates expressions, and based on the results, directs the data row to the specified stream.

Box 1: dept==\’ecommerce\’, dept==\’retail\’, dept==\’wholesale\’ First we put the condition. The order must match
the stream labeling we define in Box 3.
Syntax:
split(
disjoint: {true | false}
) ~> @(stream1, stream2, …, )
Box 2: discount : false
disjoint is false because the data goes to the first matching condition. All remaining rows matching the third condition go
to output stream all.
Box 3: eCommerce, retail, wholesale, all
Label the streams
Q9:
HOTSPOT
You need to collect application metrics, streaming query events, and application log messages for an Azure Databrick
cluster.
Which type of library and workspace should you implement? To answer, select the appropriate options in the answer
area.
NOTE: Each correct selection is worth one point.
Hot Area:
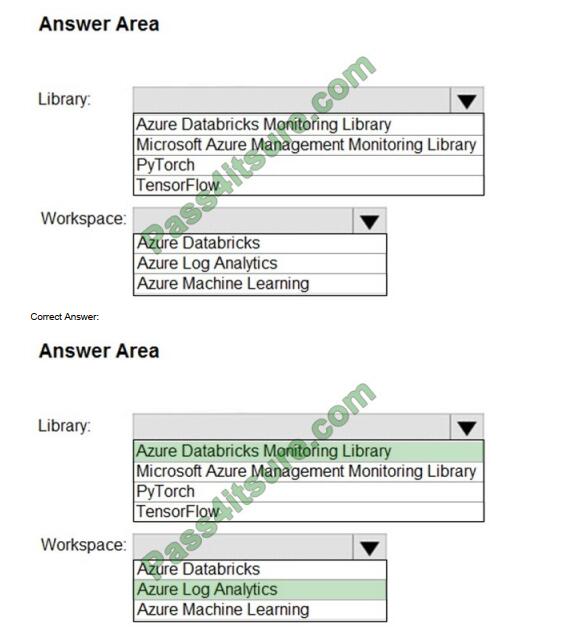
You can send application logs and metrics from Azure Databricks to a Log Analytics workspace. It uses the Azure
Databricks Monitoring Library, which is available on GitHub.
Reference: https://docs.microsoft.com/en-us/azure/architecture/databricks-monitoring/application-logs
Correct answer posted
| q1 | q2 | q3 | q4 | q5 | q6 | q7 | q8 | q9 |
| D | BD | C | C | D | A | picture | picture | picture |
Latest [2022] Microsoft DP-203 dumps PDF free
from [Google Drive] free download https://drive.google.com/file/d/1Ga10fjh3xU9boScz_CrnPkqWM7X4m6zd/view?usp=sharing DP-203 dumps pdf 2022
Summary
While Microsoft DP-203 dumps need to be refined, they will be the best way to take the exam anyway and will be the most popular among test takers.
Trying to embrace and learn them will not only improve your test scores but also allow you to break through the ceiling and see the bigger world.
I’m Microsoft-Technet, and I share Microsoft certification information to help you get satisfactory results.
Write at the end
Share the latest Microsoft DP-203 dumps link address to help you provide some suggestions worthy of reference:
Microsoft DP-203 dumps 2022 https://www.pass4itsure.com/dp-203.html (PDF+VCE)
Free DP-203 dumps pdf https://drive.google.com/file/d/1Ga10fjh3xU9boScz_CrnPkqWM7X4m6zd/view?usp=sharing