A realistic Microsoft DP-203 exam dumps [2022] are a reliable source for your Microsoft Data Engineering on Microsoft Azure exam success.
Visit here for the latest Pass4itSure DP-203 exam dumps https://www.pass4itsure.com/dp-203.html (PDF, Software, Software+ PDF) 243+ verified questions and answers.
Azure Data Engineer Associate DP-203 Exam Dumps (2022)
We have updated the free DP-203 exam dumps. Contains 13 new exam questions to help you pass the DP-203 exam effectively.
Experience The Free DP-203 Dumps Practice Test Questions
Q1
You create an Azure Databricks cluster and specify an additional library to install. When you attempt to load the library to a notebook, the library is not found. You need to identify the cause of the issue. What should you review?
A. notebook logs
B. cluster event logs
C. global init scripts logs
D. workspace logs
Cluster-scoped Init Scripts: Init scripts are shell scripts that run during the startup of each cluster node before the Spark
driver or worker JVM starts. Databricks customers use init scripts for various purposes such as installing custom
libraries, launching background processes, or applying enterprise security policies.
Logs for Cluster-scoped init scripts are now more consistent with Cluster Log Delivery and can be found in the same
root folder as driver and executor logs for the cluster.
Reference: https://databricks.com/blog/2018/08/30/introducing-cluster-scoped-init-scripts.html
Q2
You plan to create an Azure Synapse Analytics dedicated SQL pool.
You need to minimize the time it takes to identify queries that return confidential information as defined by the
company\\’s data privacy regulations and the users who executed the queues.
Which two components should you include in the solution? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. sensitivity-classification labels applied to columns that contain confidential information
B. resource tags for databases that contain confidential information
C. audit logs sent to a Log Analytics workspace
D. dynamic data masking for columns that contain confidential information
A: You can classify columns manually, as an alternative or in addition to the recommendation-based classification:
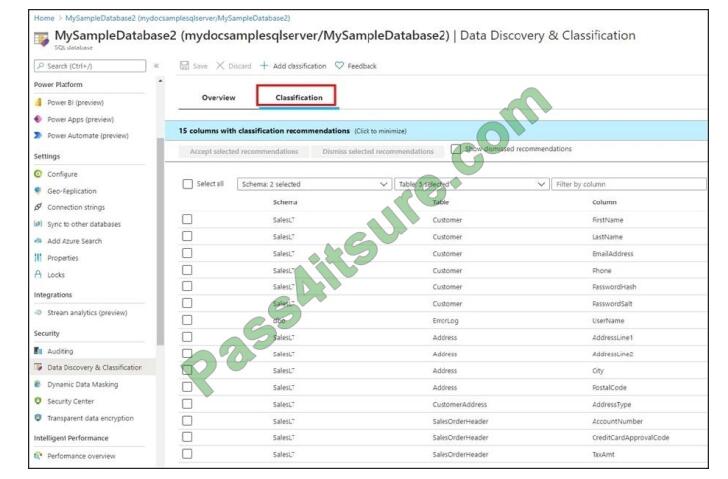
1. Select Add classification in the top menu of the pane.
2. In the context window that opens, select the schema, table, and column that you want to classify, and the information type and sensitivity label.
3. Select Add classification at the bottom of the context window.
C: An important aspect of the information-protection paradigm is the ability to monitor access to sensitive data. Azure
SQL Auditing has been enhanced to include a new field in the audit log called data_sensitivity_information. This field
logs the sensitivity classifications (labels) of the data that was returned by a query. Here\\’s an example:

Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/data-discovery-and-classification-overview
Q3
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear on the review screen. You are designing an Azure Stream Analytics solution that will analyze Twitter data.
You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only
once.
Solution: You use a session window that uses a timeout size of 10 seconds.
Does this meet the goal?
A. Yes
B. No
Instead, use a tumbling window. Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time
intervals.
Reference: https://docs.microsoft.com/en-us/stream-analytics-query/tumbling-window-azure-stream-analytics
Q4
You have an Azure Factory instance named DF1 that contains a pipeline named PL1.PL1 includes a tumbling window
trigger.
You create five clones of PL1. You configure each clone pipeline to use a different data source.
You need to ensure that the execution schedules of the clone pipeline match the execution schedule of PL1.
What should you do?
A. Add a new trigger to each cloned pipeline
B. Associate each cloned pipeline to an existing trigger.
C. Create a tumbling window trigger dependency for the trigger of PL1.
D. Modify the Concurrency setting of each pipeline.
Q5
You have an Azure Synapse Analytics dedicated SQL pool.
You run PDW_SHOWSPACEUSED(dbo,FactInternetSales\\’); and get the results shown in the following table.
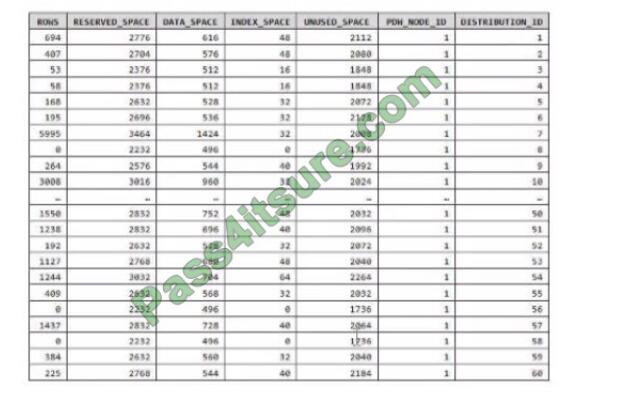
Which statement accurately describes the dbo, FactInternetSales table?
A. The table contains less than 1,000 rows.
B. All distributions contain data.
C. The table is skewed.
D. The table uses round-robin distribution.
Data skew means the data is not distributed evenly across the distributions.
Q6
You are implementing a batch dataset in the Parquet format.
Data files will be produced by using Azure Data Factory and stored in Azure Data Lake Storage Gen2. The files will be
consumed by an Azure Synapse Analytics serverless SQL pool. You need to minimize storage costs for the solution.
What should you do?
A. Store all the data as strings in the Parquet tiles.
B. Use OPENROWEST to query the Parquet files.
C. Create an external table mat containing a subset of columns from the Parquet files.
D. Use Snappy compression for the files.
An external table points to data located in Hadoop, Azure Storage blob, or Azure Data Lake Storage. External tables are
used to read data from files or write data to files in Azure Storage. With Synapse SQL, you can use external tables to
read external data using a dedicated SQL pool or serverless SQL pool.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-tables-external-tables
Q7
HOTSPOT
You have an Apache Spark DataFrame named temperatures. A sample of the data is shown in the following table.
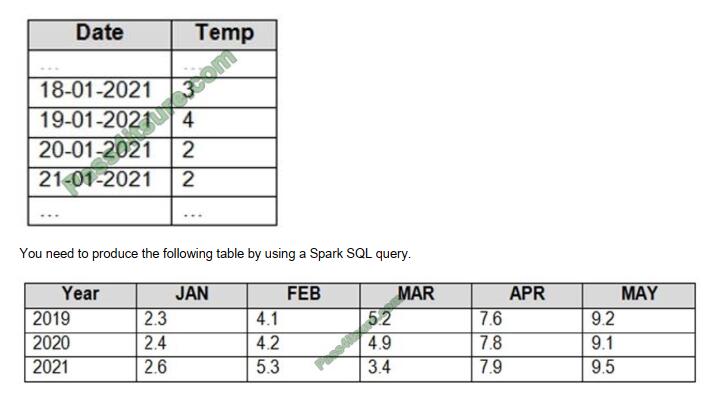
How should you complete the query? To answer, drag the appropriate values to the correct targets. Each value may be
used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

Box 1: PIVOT
PIVOT rotates a table-valued expression by turning the unique values from one column in the expression into multiple
columns in the output. And PIVOT runs aggregations where they\’re required on any remaining column values that are
wanted in the final output.
Incorrect Answers:
UNPIVOT carries out the opposite operation to PIVOT by rotating columns of a table-valued expression into column
values.
Box 2: CAST
If you want to convert an integer value to a DECIMAL data type in SQL Server use the CAST() function.
Example: SELECT CAST(12 AS DECIMAL(7,2) ) AS decimal_value;
Here is the result: decimal_value 12.00
Reference: https://learnsql.com/cookbook/how-to-convert-an-integer-to-a-decimal-in-sql-server/
https://docs.microsoft.com/en-us/sql/t-sql/queries/from-using-pivot-and-unpivot
Q8
You use Azure Stream Analytics to receive data from Azure Event Hubs and to output the data to an Azure Blob
Storage account.
You need to output the count of records received from the last five minutes every minute.
Which windowing function should you use?
A. Session
B. Tumbling
C. Sliding
D. Hopping
Q9
HOTSPOT
You are building an Azure Data Factory solution to process data received from Azure Event Hubs, and then ingested
into an Azure Data Lake Storage Gen2 container.
The data will be ingested every five minutes from devices into JSON files. The files have the following naming pattern.
/{deviceType}/in/{YYYY}/{MM}/{DD}/{HH}/{deviceID}_{YYYY}{MM}{DD}HH}{mm}.json
You need to prepare the data for batch data processing so that there is one dataset per hour per device type. The
solution must minimize read times.
How should you configure the sink for the copy activity? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

Box 1: @trigger().startTime
startTime: A date-time value. For basic schedules, the value of the startTime property applies to the first occurrence. For complex schedules, the trigger starts no sooner than the specified start time value.
Box 2: /{YYYY}/{MM}/{DD}/{HH}_{deviceType}.json
One dataset per hour per device type.
Box 3: Flatten hierarchy
– FlattenHierarchy: All files from the source folder are in the first level of the target folder. The target files have
autogenerated names.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/concepts-pipeline-execution-triggers
https://docs.microsoft.com/en-us/azure/data-factory/connector-file-system
Q10
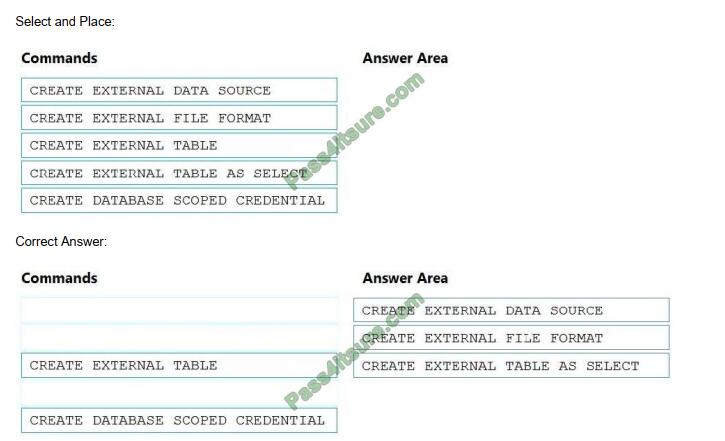
DRAG-DROP
You need to ensure that the Twitter feed data can be analyzed in the dedicated SQL pool. The solution must meet the
customer sentiment analytic requirements. Which three Transact-SQL DDL commands should you run in sequence? To answer, move the appropriate commands from the list of commands to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
Scenario: Allow Contoso users to use PolyBase in an Azure Synapse Analytics dedicated SQL pool to query the content
of the data records that host the Twitter feeds. Data must be protected by using row-level security (RLS). The users
must be authenticated by using their own Azure AD credentials.
Box 1: CREATE EXTERNAL DATA SOURCE
External data sources are used to connect to storage accounts.
Box 2: CREATE EXTERNAL FILE FORMAT
CREATE EXTERNAL FILE FORMAT creates an external file format object that defines external data stored in Azure
Blob Storage or Azure Data Lake Storage. Creating an external file format is a prerequisite for creating an external
table.
Box 3: CREATE EXTERNAL TABLE AS SELECT
When used in conjunction with the CREATE TABLE AS SELECT statement, selecting from an external table imports
data into a table within the SQL pool. In addition to the COPY statement, external tables are useful for loading data.
Incorrect Answers:
CREATE EXTERNAL TABLE
The CREATE EXTERNAL TABLE command creates an external table for Synapse SQL to access data stored in Azure
Blob Storage or Azure Data Lake Storage.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-tables-external-tables
Q11
You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and a database named DB1. DB1 contains a
fact table named Table1.
You need to identify the extent of the data skew in Table1.
What should you do in Synapse Studio?
A. Connect to the built-in pool and run DBCC PDW_SHOWSPACEUSED.
B. Connect to the built-in pool and run DBCC CHECKALLOC.
C. Connect to Pool1 and query sys.dm_pdw_node_status.
D. Connect to Pool1 and query sys.dm_pdw_nodes_db_partition_stats.
Microsoft recommends the use of sys.dm_pdw_nodes_db_partition_stats to analyze any skewness in the data.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/cheat-sheet
Q12
You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Table1.
You have files that are ingested and loaded into an Azure Data Lake Storage Gen2 container named container1.
You plan to insert data from the files into Table1 and Azure Data Lake Storage Gen2 container named container1.
You plan to insert data from the files into Table1 and transform the data. Each row of data in the files will produce one
row in the serving layer of Table1.
You need to ensure that when the source data files are loaded to container1, the DateTime is stored as an additional column in Table1.
Solution: In an Azure Synapse Analytics pipeline, you use a data flow that contains a Derived Column transformation.
Does this meet the goal?
A. Yes
B. No
Use the derived column transformation to generate new columns in your data flow or to modify existing fields.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/data-flow-derived-column
Q13
You are designing an Azure Synapse Analytics workspace.
You need to recommend a solution to provide double encryption of all the data at rest.
Which two components should you include in the recommendation? Each coned answer presents part of the solution
NOTE: Each correct selection is worth one point.
A. an X509 certificate
B. an RSA key
C. an Azure key vault that has purge protection enabled
D. an Azure virtual network that has a network security group (NSG)
E. an Azure Policy initiative
Answers:
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | Q10 | Q11 | Q12 | Q13 |
| C | AC | B | B | C | C | see picture | D | see picture | see picture | D | A | AD |
Also Updated, DP-203 Free Dumps PDF
[NEW] DP-203 exam dumps pdf https://drive.google.com/file/d/1S76il7PoxmhhX1qXn06W7FT7Ac0Y94gx/view?usp=sharing
The true Microsoft DP-203 exam dumps 2022 https://www.pass4itsure.com/dp-203.html will help you prepare to get good results in one go with a 100% guarantee.